Концепции многозадачности
Что не так с синхронным кодом?
Типичное приложение — это цикл: получить запрос, обработать, отправить ответ. Пока обработка идёт, всё остальное стоит. Если один запрос занимает 2 секунды (сходить в базу, вызвать внешний API, прочитать файл), то следующий пользователь ждёт в очереди. Десять таких запросов — двадцать секунд простоя.
Синхронный код работает, пока задач мало и они быстрые. Но как только появляются I/O-ожидания (сеть, диск, база) или тяжёлые вычисления — однопоточная модель становится узким местом. Нужны инструменты, которые позволяют делать несколько вещей одновременно.
Терминология: параллельность, конкурентность, асинхронность
Эти термины часто путают. Разберём точно:
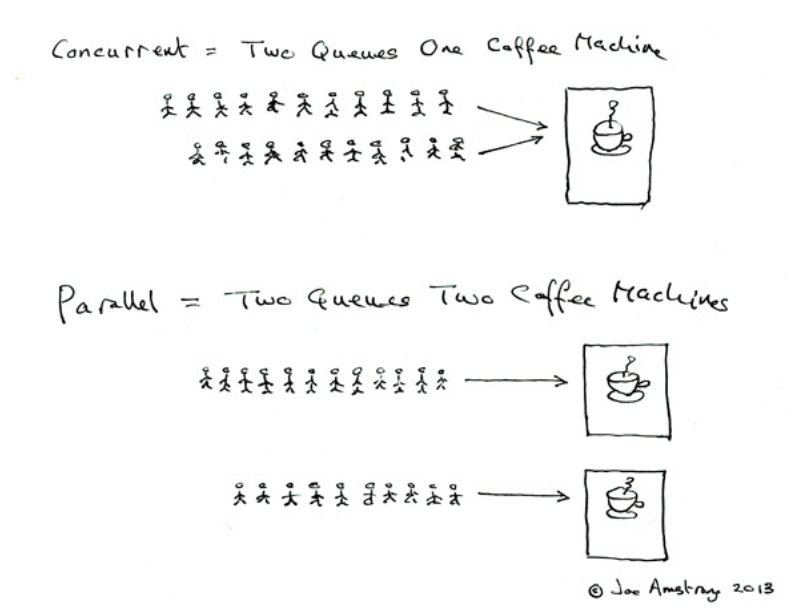
Конкурентность (concurrency) — способность обрабатывать несколько задач, чередуя выполнение или параллельно, чтобы все они в конечном итоге завершились. Одноядерный процессор способен к конкурентности: планировщик ОС �чередует задачи, создавая иллюзию одновременности. Синоним — многозадачность (multitasking).
Параллелизм (parallelism) — способность выполнять несколько вычислений одновременно, в буквальном смысле, в один момент времени. Требует многоядерного процессора, GPU или кластера. Параллелизм — частный случай конкурентности.
Асинхронность (asynchrony) — подход, при котором задача запускается и выполняется в фоне, а основной поток продолжает работу без ожидания. Когда операция завершается, результат возвращается через механизм обратного вызова (callback) или ожидание (await).
Конкурентность — про структуру программы (задачи могут выполняться независимо). Параллелиз�м — про выполнение (задачи выполняются одновременно на разных ядрах). Программа может быть конкурентной, но не параллельной — например, на одноядерной машине.
CPU-bound vs I/O-bound
Прежде чем выбирать инструмент (потоки, процессы, async), нужно понять тип задачи:
| CPU-bound | I/O-bound | |
|---|---|---|
| Что занимает время | Вычисления на процессоре | Ожидание внешних устройств (сеть, диск, БД) |
| Примеры | Обработка изображений, шифрование, ML-инференс, парсинг | HTTP-запросы, чтение файлов, запросы к БД, вызовы API |
| Как ускорить | Параллелизм (несколько ядер) | Конкурентность (не ждать, а переключаться) |
| Инструмент в Python | ProcessPoolExecutor, multiprocessing | ThreadPoolExecutor, asyncio |
Как говорил Дэвид Бизли: «Потоки хороши в том, чтобы ничего не делать» — то есть ждать I/O, пока процессор свободен.
Даже на одном ядре ОС чередует задачи, выделяя каждой короткий квант времени. Это создаёт иллюзию параллельности, но общее время не уменьшается — к нему добавляется стоимость переключения контекста. Настоящее ускорение даёт только многоядерный параллелизм.
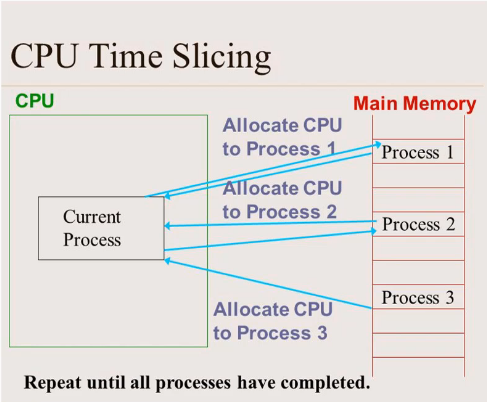
Процессы и потоки на уровне ОС
Процесс
Процесс — экземпляр выполняющейся программы. У каждого процесса изолированное состояние:
- виртуальное адресное пространство,
- указатель на текущую инструкцию,
- стек вызовов,
- системные ресурсы (открытые файловые дескрипторы, сокеты).
Процессы удобны для одновременного выполнения независимых задач — они не могут случайно повредить память друг друга.
Поток (thread)
Поток исполняется внутри процесса и разделяет с ним адресное пространство и ресурсы. Создание потока дешевле создания процесса. Потоки удобны, когда задачам нужен доступ к общим данным.
Совместным выполнением потоков и процессов управляет операционная система, поочерёдно предоставляя каждому кванты процессорного времени.
| Характеристика | Процессы | Потоки |
|---|---|---|
| Память | Изолированная | Общая |
| Создание | Дорогое (~100 мс) | Дешёвое (~1 мс) |
| Обмен данными | IPC (pipes, queues, shared memory) | Прямой доступ к общей памяти |
| Изоляция | Полная — сбой одного процесса не затрагивает другой | Сбой потока может уронить весь процесс |
GIL — ограничение Python
GIL (Global Interpreter Lock) — мьютекс, который гарантирует, что в каждый момент времени только один поток выполняет байткод Python.
Зачем GIL существует
CPython управляет памятью через подсчёт ссылок: каждый объект хранит счётчик ссылок, и когда он достигает нуля — объект удаляется. Без GIL несколько потоков могли бы одновременно изменять счётчик ссылок одного объекта, что приводило бы к повреждению данных или утечкам памяти.
GIL — это компромисс: простая и надёжная реализация ценой невозможности параллельного выполнения Python-байткода в потоках.
Когда GIL мешает, а когда — нет
GIL не мешает при I/O-bound задачах: GIL освобождается, когда поток ждёт ввода-вывода (сетевой запрос, чтение файла, time.sleep()). Пока один поток ждёт ответа сервера, другой может обрабатывать данные.
GIL мешает при CPU-bound задачах: несколько потоков не ускоря�ют вычисления, а иногда даже замедляют из-за накладных расходов на переключение и конкуренцию за GIL.
import threading, time
def cpu_task(n):
"""CPU-bound: потоки НЕ ускорят из-за GIL"""
return sum(i * i for i in range(n))
def io_task(seconds):
"""I/O-bound: GIL отпускается при sleep/сети/диске"""
time.sleep(seconds)
# CPU-bound: 2 потока ≈ такое же время, как 1 поток
# I/O-bound: 2 потока ≈ в 2 раза быстрее
Плюсы и минусы GIL
| Плюсы | Минусы |
|---|---|
| Простая и надёжная реализация CPython | Потоки не параллелят CPU-bound задачи |
| Упрощённый подсчёт ссылок | Ограниченное масштабирование на многоядерных CPU |
| Предсказуемая производительность | Обходные пути (multiprocessing, C-расширения) добавляют сложность |
| Безопасный доступ к Python-объектам из C-расширений |
Python C API предоставляет макросы Py_BEGIN_ALLOW_THREADS / Py_END_ALLOW_THREADS для освобождения GIL в C-расширениях. Это безопасно только при работе с данными, не связанными с Python-объектами. Все стандартные блокирующие I/O-операции CPython используют эту механику.
Модуль threading
Поток в Python — это системный поток (thread ОС), управляемый операционной системой, а не интерпретатором. Создать поток можно через класс Thread из модуля threading.
Создание потока
import threading
import time
def worker(name, delay):
print(f"{name} started")
time.sleep(delay)
print(f"{name} finished")
t1 = threading.Thread(target=worker, args=("Thread-1", 2))
t2 = threading.Thread(target=worker, args=("Thread-2", 1))
t1.start() # запускает поток
t2.start()
t1.join() # ждём завершения t1
t2.join() # ждём завершения t2
print("All done")
Метод start() запускает поток, join() — блокирует вызывающий поток до завершения целевого. Повторные вызовы join() не имеют эффекта.
Создание потока через наследование
from threading import Thread
import time
class CountdownThread(Thread):
def __init__(self, n):
super().__init__()
self.n = n
def run(self):
for i in range(self.n):
print(self.n - i - 1, "left")
time.sleep(1)
t = CountdownThread(3)
t.start()
Документация рекомендует переопределять только __init__() и run() — другие методы класса Thread не предназначены для расширения.
Имя и идентификатор потока
Каждому потоку можно задать имя, по умолчанию оно формируется как "Thread-N" (начиная с Python 3.10, если задан target, имя будет "Thread-N (target_name)"):
from threading import Thread
t = Thread(target=print, args=("hello",))
print(t.name) # "Thread-1 (print)"
t = Thread(name="MyWorker")
print(t.name) # "MyWorker"
t.start()
print(t.ident) # числовой id, уникальный для активных потоков
print(t.native_id) # id на уровне ОС (Python 3.8+)
Получение списка потоков
import threading
# Список всех активных потоков
for t in threading.enumerate():
print(t.name, t.is_alive())
# MainThread True
Основной поток и daemon-потоки
При запуске программы интерпретатор работает внутри MainThread. Когда основной поток завершается, судьба остальных зависит от их типа:
- Обычные потоки — программа ждёт их завершения перед выходом.
- Daemon-потоки (
daemon=True) — автоматически уничтожаются при завершении основного потока, без финализации. Не используйте демонов для задач с ресурсами (файлы, соединения), которые нужно корректно закрыть.
import threading, time
def background_task():
while True:
print("Working...")
time.sleep(1)
# daemon=True — поток не помешает завершению программы
t = threading.Thread(target=background_task, daemon=True)
t.start()
time.sleep(3)
print("Main thread done")
# Программа завершится, daemon будет убит
Завершение потоков
В Python нет встроенного механизма принудительного завершения потоков — это осознанное решение, потому что поток может удерживать ресурсы (файлы, блокировки). Стандартный паттерн — флаг остановки:
import threading, time
class StoppableWorker(threading.Thread):
def __init__(self):
super().__init__()
self._stop_event = threading.Event()
def stop(self):
self._stop_event.set()
def run(self):
while not self._stop_event.is_set():
print("Working...")
self._stop_event.wait(timeout=1) # проверяем каждую секунду
print("Stopped gracefully")
w = StoppableWorker()
w.start()
time.sleep(3)
w.stop()
w.join()
Пример: spinner-анимация
Классический пример использования потоков — анимация загрузки в консоли, пока основной поток выполняет вычисление:
import threading
import time
import itertools
def spin(msg, done_event):
for char in itertools.cycle(r"\|/-"):
if done_event.is_set():
break
print(f"\r{char} {msg}", end="", flush=True)
time.sleep(0.1)
print(f"\r✓ {msg}")
def slow_computation():
time.sleep(3) # имитация тяжёлого вычисления
return 42
done = threading.Event()
spinner = threading.Thread(target=spin, args=("Computing...", done))
spinner.start()
result = slow_computation()
done.set()
spinner.join()
print(f"Result: {result}")
Обработка исключений в потоках
По умолчанию необработанное исключение в потоке выводится в stderr, но не останавливает программу. С Python 3.8 можно перехватить такие исключения через threading.excepthook:
import threading
def custom_hook(args):
print(f"Exception in {args.thread.name}: {args.exc_type.__name__}: {args.exc_value}")
threading.excepthook = custom_hook
def buggy():
raise ValueError("something went wrong")
t = threading.Thread(target=buggy)
t.start()
t.join()
Примитивы синхронизации
Когда несколько потоков работают с общими данными, нужны механизмы синхронизации — иначе возникают гонки (race conditions).
Race condition
Гонка (race condition) возникает, когда результат зависит от порядка выполнения потоков:
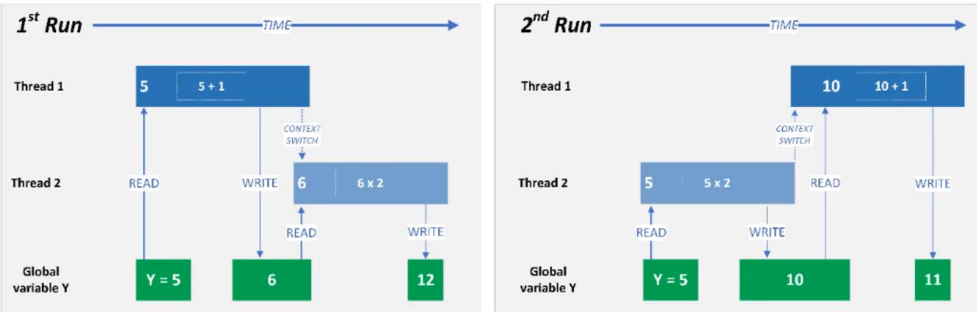
Классический пример — неатомарный инкремент:
import threading
counter = 0
def increment():
global counter
for _ in range(100_000):
counter += 1 # read → modify → write (3 шага!)
threads = [threading.Thread(target=increment) for _ in range(4)]
for t in threads: t.start()
for t in threads: t.join()
print(counter) # Ожидаем 400000, получаем меньше!
Операция counter += 1 выглядит атомарной, но на уровне байткода это три шага: загрузить значение, прибавить 1, записать обратно. Между шагами может вклиниться другой поток.
Lock (мьютекс)
Lock — простейший примитив синхронизации. Гарантирует, что критическую секцию одновременно выполняет только один п�оток:
import threading
counter = 0
lock = threading.Lock()
def safe_increment():
global counter
for _ in range(100_000):
with lock: # acquire → ... → release
counter += 1
threads = [threading.Thread(target=safe_increment) for _ in range(4)]
for t in threads: t.start()
for t in threads: t.join()
print(counter) # Всегда 400000
В CPython у Lock нет понятия владеющего потока — любой поток может вызвать release(), даже если не он вызывал acquire(). Это отличает его от мьютексов во многих других языках. Если нужна привязка к потоку — используйте RLock.
RLock (реентерабельный мьютекс)
RLock позволяет одному потоку захватывать блокировку несколько раз (например, при рекурсии). Каждый acquire() требует соответствующий release():
import threading
rlock = threading.RLock()
def recursive_task(n):
with rlock:
if n > 0:
print(f"Level {n}")
recursive_task(n - 1) # повторный захват того же rlock — OK
recursive_task(3)
Deadlock и как его избежать
Deadlock — состояние бесконечной взаимной блокировки:
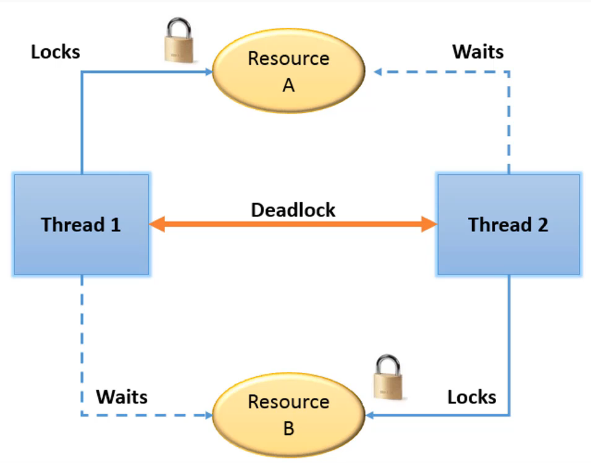
Возникает, когда:
- два потока ждут блокировки друг друга,
- поток рекурсивно захв�атывает обычный
Lock(неRLock).
lock_a = threading.Lock()
lock_b = threading.Lock()
# Поток 1: lock_a → lock_b
# Поток 2: lock_b → lock_a → DEADLOCK!
Как избежать:
- Захватывайте блокировки всегда в одном порядке
- Используйте
RLockпри рекурсии - Задавайте таймауты:
lock.acquire(timeout=5)
Semaphore
Semaphore ограничивает количество потоков, одновременно имеющих доступ к ресурсу:
import threading, time
# Максимум 3 одновременных подключения
pool_sema = threading.Semaphore(3)
def connect(name):
with pool_sema:
print(f"{name} connected")
time.sleep(2)
print(f"{name} disconnected")
threads = [threading.Thread(target=connect, args=(f"Client-{i}",)) for i in range(10)]
for t in threads: t.start()
BoundedSemaphore дополнительно проверяет, что release() не вызывается больше раз, чем acquire() — защита от багов.
Event
Event — механизм сигнализации между потоками. Один поток ждёт (wait()), другой сигнализирует (set()):
import threading
event = threading.Event()
def waiter():
print("Waiting for signal...")
event.wait() # блокируется до set()
print("Got signal!")
def signaler():
import time
time.sleep(2)
print("Sending signal")
event.set() # разблокирует все ожидающие
threading.Thread(target=waiter).start()
threading.Thread(target=signaler).start()
Barrier
Barrier — точка синхронизации, где N потоков ожидают друг друга перед продолжением:
import threading
barrier = threading.Barrier(3)
def stage_worker(name):
print(f"{name}: stage 1 done")
barrier.wait() # ждём, пока все 3 будут здесь
print(f"{name}: stage 2 started")
for i in range(3):
threading.Thread(target=stage_worker, args=(f"Worker-{i}",)).start()
Полный список примитивов синхронизации
| Примитив | Назначение |
|---|---|
Lock | Эксклюзивный доступ (мьютекс) |
RLock | Реентерабельный мьютекс (можно захватывать повторно из того же потока) |
Condition | Объединяет Lock и Event — ожидание с условием |
Semaphore | Ограничение числа одновременных доступов |
BoundedSemaphore | Semaphore с защитой от лишних release() |
Event | Сигнализация между потоками |
Barrier | Ожидание N потоков в точке синхронизации |
Queue для межпоточного обмена
queue.Queue — потокобезопасная очередь для обмена данными между потоками. Это предпочтительный способ пер�едачи данных, так как он избавляет от ручной синхронизации:
from queue import Queue
import threading
q = Queue(maxsize=10) # ограниченная очередь
def producer():
for i in range(5):
q.put(f"item-{i}")
print(f"Produced item-{i}")
q.put(None) # сигнал завершения (sentinel)
def consumer():
while True:
item = q.get()
if item is None:
break
print(f"Consumed: {item}")
q.task_done()
t1 = threading.Thread(target=producer)
t2 = threading.Thread(target=consumer)
t1.start()
t2.start()
t1.join()
t2.join()
С Python 3.7 также доступен queue.SimpleQueue — упрощённая FIFO-очередь без task_done() / join(), но быстрее для простых сценариев.
Модуль multiprocessing
Если задача CPU-bound и потоки не помогают из-за GIL — используйте процессы. У каждого процесса свой интерпретатор со �своим GIL, поэтому они действительно выполняются параллельно на нескольких ядрах.
Создание процесса
API multiprocessing намеренно повторяет API threading:
from multiprocessing import Process
def heavy_computation(name, n):
result = sum(i * i for i in range(n))
print(f"{name}: {result}")
if __name__ == "__main__":
p = Process(target=heavy_computation, args=("Worker", 10**7))
p.start()
print(f"PID: {p.pid}, name: {p.name}")
p.join()
print(f"Exit code: {p.exitcode}")
if __name__ == "__main__"На Windows и macOS (метод запуска spawn) дочерний процесс импортирует модуль заново. Без защиты if __name__ == "__main__" код создания процесса выполнится рекурсивно.
Pool — пул процессов
from multiprocessing import Pool
def square(n):
return n ** 2
if __name__ == "__main__":
with Pool(4) as pool:
results = pool.map(square, range(10))
print(results) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
Данные между процессами передаются через сериализацию (pickle). Это значит:
- Локальные (вложенные) функции нельзя передать — pickle не может их сериализовать
- Большие объекты передаются медленно — overhead сериализации
from multiprocessing import Pool
def calc_parallel(values):
def calc(value): # вложенная функция!
return value ** 2
p = Pool(processes=2)
return p.map(calc, values) # PicklingError!
# Решение: вынесите calc на уровень модуля
Обмен данными между процессами
Pipe — двустороннее соединение между двумя процессами:
from multiprocessing import Process, Pipe
def sender(conn):
conn.send({"status": "ok", "value": 42})
conn.close()
if __name__ == "__main__":
parent_conn, child_conn = Pipe()
p = Process(target=sender, args=(child_conn,))
p.start()
print(parent_conn.recv()) # {'status': 'ok', 'value': 42}
p.join()
multiprocessing.Queue — аналог queue.Queue, но для процессов.
shared_memory (Python 3.8+)
Для больших данных (массивы, матрицы) сериализация через pickle слишком медленная. multiprocessing.shared_memory позволяет процессам работать с общим блоком памяти напрямую:
from multiprocessing import shared_memory, Process
import struct
def writer(shm_name):
shm = shared_memory.SharedMemory(name=shm_name)
struct.pack_into("i", shm.buf, 0, 42)
shm.close()
if __name__ == "__main__":
shm = shared_memory.SharedMemory(create=True, size=4)
p = Process(target=writer, args=(shm.name,))
p.start()
p.join()
value = struct.unpack_from("i", shm.buf, 0)[0]
print(value) # 42
shm.close()
shm.unlink()
Методы запуска процессов
multiprocessing поддерживает три метода запуска:
| Метод | ОС | Описание |
|---|---|---|
fork | Linux, macOS | Копирует процесс целиком. Быстро, но небезопасно с потоками |
spawn | Все | Запускает новый интерпретатор, импортирует модуль. Безопасно, но медленнее |
forkserver | Linux | Компромисс: один fork-сервер порождает процессы |
По умолчанию: spawn на Windows и macOS, fork на Linux (но fork может стать deprecated в будущих версиях).
import multiprocessing as mp
mp.set_start_method("spawn") # вызвать один раз, в начале
# или использовать контекст:
ctx = mp.get_context("spawn")
p = ctx.Process(target=...)
concurrent.futures — единый API
Модуль concurrent.futures предоставляет единый интерфейс для параллельного выполнения через потоки или процессы. Нужно переключиться с потоков на процессы? Замените один класс.
ThreadPoolExecutor и ProcessPoolExecutor
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import time
def download(url):
time.sleep(1) # имитация сетевого запроса
return f"Downloaded {url}"
def compute(n):
return sum(i ** 2 for i in range(n))
# I/O-bound → потоки
with ThreadPoolExecutor(max_workers=5) as executor:
results = list(executor.map(download, ["url1", "url2", "url3"]))
# CPU-bound → процессы
if __name__ == "__main__":
with ProcessPoolExecutor(max_workers=4) as executor:
results = list(executor.map(compute, [10**6] * 8))
Future — обёртка над асинхронным результатом
executor.submit() возвращает объект Future, представляющий будущий результат:
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor(max_workers=4) as executor:
f = executor.submit(sorted, [4, 3, 1, 2])
f.running() # выполняется ли сейчас?
f.done() # завершилось ли?
f.cancelled() # было ли отменено?
f.result() # [1, 2, 3, 4] — блокирует до результата
f.exception() # None (или исключение)
f.add_done_callback(lambda fut: print(f"Done: {fut.result()}"))
as_completed и wait
as_completed() возвращает futures по мере завершения (а не в порядке отправки):
from concurrent.futures import ThreadPoolExecutor, as_completed
import time, random
def task(n):
time.sleep(random.uniform(0.5, 2))
return n * 10
with ThreadPoolExecutor(max_workers=3) as executor:
futures = {executor.submit(task, i): i for i in range(5)}
for future in as_completed(futures):
original = futures[future]
try:
result = future.result()
print(f"Task {original} → {result}")
except Exception as e:
print(f"Task {original} failed: {e}")
wait() позволяет ждать определённого условия:
from concurrent.futures import ThreadPoolExecutor, wait, FIRST_COMPLETED
with ThreadPoolExecutor(max_workers=3) as executor:
futures = [executor.submit(task, i) for i in range(5)]
# Дождаться первого завершившегося
done, not_done = wait(futures, return_when=FIRST_COMPLETED)
print(f"First result: {done.pop().result()}")
Доступные режимы: FIRST_COMPLETED, FIRST_EXCEPTION, ALL_COMPLETED.
Эволюция GIL: от ограничения к свободе
GIL — не вечная часть Python. С версии 3.12 идёт активная работа по его удалению:
Python 3.12: субинтерпретаторы (PEP 684)
Глобальное состояние интерпретатора разделили по субинтерпретаторам, позволив каждому иметь собственный GIL. Ключевые изменения:
- Глобальные структуры (аллокатор
obmallocи др.) перенесены вPyInterpreterState - Введены «бессмертные» объекты (PEP 683) —
None,True,False, маленькие целые — с фиксированным счётчиком ссылок, безопасным для разделения между интерпретаторами
Python 3.13: экспериментальный no-GIL (PEP 703)
PEP 703 (автор — Sam Gross) сделал GIL опциональным. Появилась free-threading сборка CPython:
- Сборка с
--disable-gil(build-time) или запуск с-X gil=0/PYTHON_GIL=0(runtime) - Статус: экспериментальный — стандартная сборка по-прежнему с GIL
- C-расширения должны явно объявлять совместимость через слот
Py_mod_gil - Заметная просадка однопоточной производительности
Проверить режим: sys._is_gil_enabled() (Python 3.13+).
Python 3.14: no-GIL становится supported (PEP 779)
- Free-threading вышел из экспериментального статуса — определены критерии зрелости (PEP 779)
- Включён адаптивный специализированный интерпретатор (PEP 659) — однопоточный overhead сократился (оценочно до ~5–10%)
- Новый модуль
concurrent.interpreters(PEP 734) — запуск изолированных интерпретаторов из Python-кода InterpreterPoolExecutorвconcurrent.futures— параллелизм как у процессов, но �с меньшими накладными расходами (общее адресное пространство)
Когда GIL уберут по умолчанию?
Точной версии не объявлено. Steering Council будет принимать решение на основе готовности экосистемы: совместимости библиотек, стабильности, производительности. Python 3.15 (2026) продолжает улучшения (JIT-компилятор), но вряд ли сделает no-GIL режимом по умолчанию. Реалистичная оценка — не раньше Python 3.16+.
Когда использовать что
| Задача | Инструмент | Почему |
|---|---|---|
| Много HTTP-запросов | ThreadPoolExecutor или asyncio | I/O-bound, GIL не мешает |
| Чтение/запись файлов | ThreadPoolExecutor | I/O-bound |
| Числовые вычисления | ProcessPoolExecutor | CPU-bound, отдельный GIL на каждый процесс |
| GUI + фоновая работа | threading.Thread | UI не блокируется |
| Обработка больших данных | ProcessPoolExecutor + shared_memory | CPU-bound + минимизация копирования |
| Много мелких CPU-задач | InterpreterPoolExecutor (Python 3.14) | Легче процессов, изоляция без pickle |
Ссылки
Документация
- threading — Thread objects
- threading — Lock objects
- multiprocessing — Process-based parallelism
- multiprocessing — Pipes and Queues
- concurrent.futures — Launching parallel tasks
- Free-threaded CPython HOWTO
PEP
- PEP 703 — Making the GIL Optional
- PEP 684 — Per-Interpreter GIL
- PEP 734 — Multiple Interpreters in the Stdlib
- PEP 779 — Criteria for Supported Free-Threaded Python