Модель данных Python
Зачем знать модель данных
Большинство Python-разработчиков пишут код, не задумываясь о том, как он устроен внутри. Для прикладных задач этого достаточно — до тех пор, пока не придётся отлаживать утечку памяти, разбираться, почему is ведёт себя не так, как ==, или объяснять на собеседовании, чем кортеж быстрее списка.
Модель данных Python — это набор правил, по которым интерпретатор �создаёт, хранит и уничтожает объекты. Понимание этих правил позволяет:
- Писать библиотеки — любой dunder-метод (
__init__,__hash__,__repr__) это часть модели данных - Оптимизировать — зная, как устроен dict или list, можно предсказать производительность
- Отлаживать — утечки памяти, неожиданные мутации, странное поведение
is— всё объясняется моделью данных - Проходить собеседования — вопросы про mutable default arguments, кэширование int и GC задают постоянно
Официальная спецификация: Data Model — Python docs.
Реализации Python
Прежде чем говорить о внутреннем устройстве, важно понимать: Python — это спецификация языка, а не конкретная программа. Существует несколько реализаций:
| Реализация | Язык | Особенности |
|---|---|---|
| CPython | C | Эталонная реализация, самая распространённая |
| PyPy | RPython | JIT-компиляция, в 4–10× быстрее CPython на вычислениях |
| Jython | Java | Работает на JVM, доступ к Java-библиотекам |
| IronPython | C# | Работает на .NET CLR |
| Cython | C/Python | Компилирует Python-подобный код в C-расширения |
В этом курсе, когда мы говорим «Python», мы имеем в виду CPython — именно его устанавливают через python.org и именно его детали реализации (кэширование int, подсчёт ссылок, GIL) мы будем разбирать. Некоторые вещи, которые мы обсуждаем (например, диапазон кэширования целых чисел) — это детали реализации CPython, а не часть спецификации языка. В других реализациях они могут отличаться.
Интроспекция
Python позволяет программе исследовать и изменять саму себя во время выполнения. Эта возможность называется интроспекцией (в Java-мире используется термин «рефлексия», в Python-сообществе принято говорить «интроспекция»):
- Можно узнать тип переменной «на лету» —
type(x),isinstance(x, int) - Можно посмотреть структуру объекта —
dir(obj),vars(obj) - Можно исполнить код, сгенерированный в рантайме —
eval(),exec() - Можно получить доступ к AST программы из самой программы
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
p = Point(1, 2)
print(type(p)) # <class '__main__.Point'>
print(dir(p)) # ['__class__', ..., 'x', 'y']
print(hasattr(p, 'x')) # True
print(vars(p)) # {'x': 1, 'y': 2}
Благодаря интроспекции работают такие инструменты, как pytest (автоматическое обнаружение тестов), Sphinx (генерация документации из docstring) и IPython (автодополнение).
Типы данных и динамическая типизация
Python использует динамическую типизацию — тип переменной определяется во время выполнения, а не при компиляции. Одна и та же переменная может последовательно ссылаться на объекты разных типов:
x = 1
print(x, type(x)) # 1 <class 'int'>
x = x * 1.5
print(x, type(x)) # 1.5 <class 'float'>
x = str(x)
print(x, type(x)) # 1.5 <class 'str'>
print(type(type(x))) # <class 'type'>
Привести один тип к другому можно с помощью встроенных функций: int(), str(), float(), list(), tuple() и т.д.
Утиная типизация (duck typing): «Если это выглядит как утка, плавает как утка и крякает как утка, то это, вероятно, и есть утка». Python не проверяет тип объекта — он проверяет, поддерживает ли объект нужный протокол (набор методов). Если вы передаёте объект в len(), Python не спрашивает «это list?» — он вызывает obj.__len__(). Есть метод — значит, подходит.
Всё — объект
В CPython каждый объект — это C-структура, унаследованная от PyObject. Даже тип объекта — это объект:
PyObject— базовая структура: хранитob_refcnt(счётчик ссылок) иob_type(указатель на тип)PyTypeObject— наследуется отPyObject, содержит информацию о dunder-методах (__init__,__str__,__hash__и т.д.)- Типы образуют иерархию:
boolнаследуется отint, который наследуется отobject
print(type(42)) # <class 'int'>
print(type(int)) # <class 'type'>
print(type(type)) # <class 'type'> — type является своим собственным типом!
print(isinstance(True, int)) # True — bool наследуется от int
print(int.__bases__) # (<class 'object'>,)
print(bool.__bases__) # (<class 'int'>,)
Спецификация: Objects, values and types.
Переменные и присваивание
Переменная в Python — не объект. Это привязка имени к объекту: либо запись в dict (для глобальных переменных), либо слот в массиве фрейма (для локальных). Сама переменная не имеет id() и не управляется сборщиком мусора.
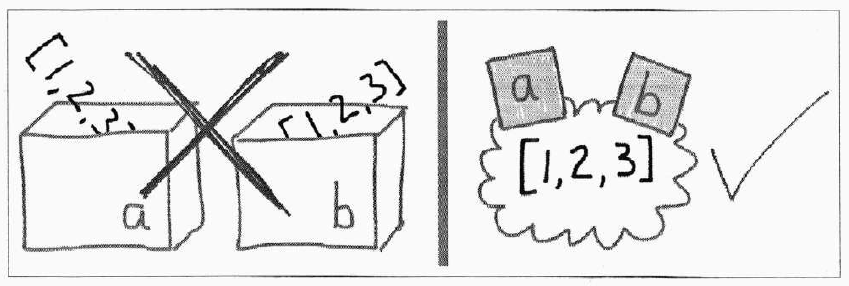
# label = object
x = 42 # имя x привязывается к объекту int(42)
y = x # y привязывается к тому же объекту
print(id(x) == id(y)) # True — один и тот же объект
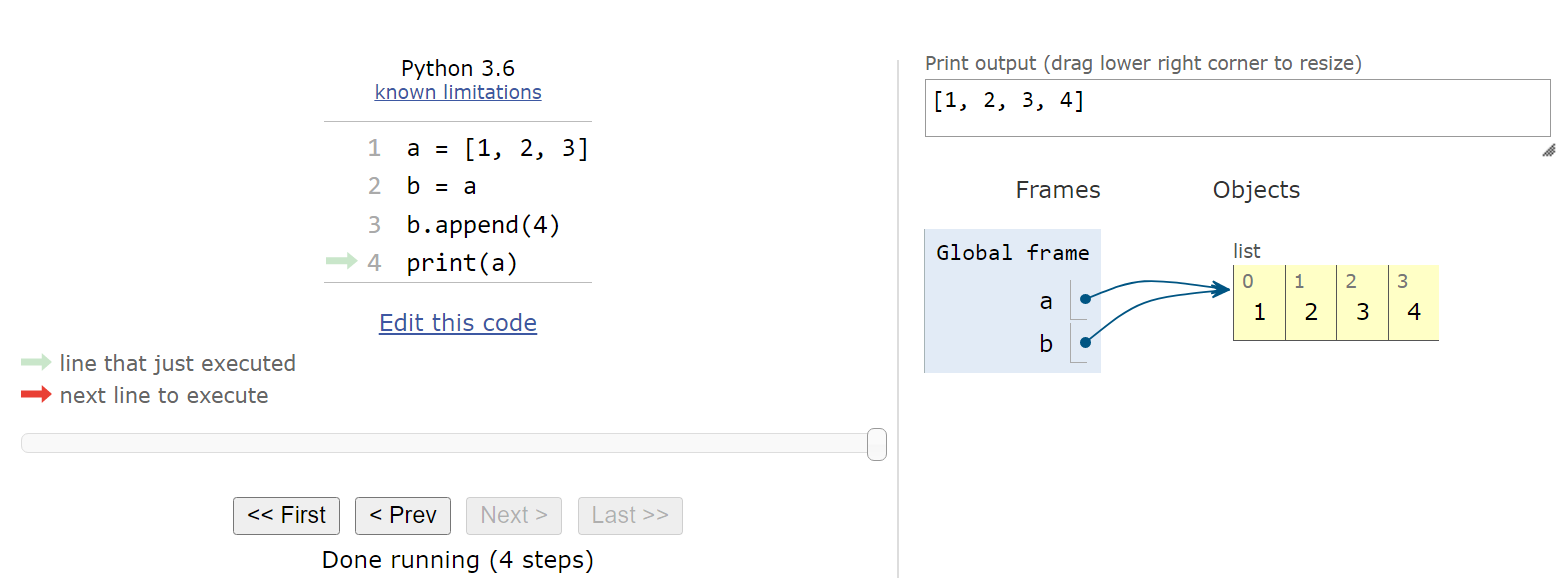
Визуализировать привязки можно с помощью Python Tutor:
Когда вы пишете nums = (1, 2), что происходит?
- Compile time: компилятор видит, что
(1, 2)— литеральный кортеж из констант, и создаёт его заранее, записывая в массивco_constsобъекта кода - Runtime: интерпретатор просто берёт готовую ссылку из
co_consts(инструкцияLOAD_CONST) — аллокации не происходит
Для list ситуация другая: литеральный [1, 2] компилируется в создание tuple-шаблона в co_consts, а в рантайме — аллоцируется пустой list и элементы копируются из шаблона. Именно поэтому кортежи работают быстрее списков.
Если не все элементы — литералы, оптимизации не будет: появятся LOAD_NAME, BUILD_LIST/BUILD_TUPLE. Все случаи можно сравнить через dis.dis().
Где хранятся переменные
- Глобальные переменные — запись в словаре модуля (
globals()) - Локальные (в функци�и) — слот в массиве фрейма, 8 байт на ссылку (x64)
До Python 3.11 при каждом вызове функции на куче аллоцировался объект фрейма. Начиная с 3.11 (PEP 659), если программа не запрашивает фрейм явно (через inspect или traceback), он создаётся лениво и живёт прямо на C-стеке интерпретатора — без вызова malloc.
Walrus-оператор (:=)
Начиная с Python 3.8 (PEP 572) появилось выражение присваивания — оно не только записывает значение, но и возвращает его:
# Без walrus — дублирование вызова
command = input("> ")
while command != "quit":
print("You entered:", command)
command = input("> ")
# С walrus — один вызов
while (command := input("> ")) != "quit":
print("You entered:", command)
# Ещё примеры
if (n := len(a)) > 10:
print(f"List is too long ({n} elements, expected <= 10)")
# Обработка файла чанками
while chunk := file.read(8192):
process(chunk)
Оператор NAME = expr — инструкция, которая ничего не возвращает. Нельзя использовать внутри других выражений.
Выражение (NAME := expr) — возвращает присвоенное значе�ние. Можно использовать внутри if, while, list comprehension и т.д.
По производительности разницы нет — walrus просто добавляет инструкцию COPY значения на стеке.
Идентичность и равенство (is vs ==)
Для сравнения объектов в Python есть два механизма:
==— проверка равенства значений (вызывает__eq__)is— проверка идентичности (один и тот же объект в памяти, одинаковыйid())
i, j = 100, 100
print(i == j, i is j) # True True — кэширование малых чисел
x, y = 10**100, 10**100
print(x == y, x is y) # True False — разные объекты с одинаковым значением
Не используйте is для сравнения значений! is проверяет идентичность объекта, а не равенство. Единственное исключение — сравнение с None: if x is None.
Кэширование малых целых чисел
CPython заранее создаёт объекты для целых чисел от −5 до 256 включительно. Когда вы пишете x = 42, Python не аллоцирует новый объект — он возвращает указатель на уже существующий. Именно поэтому 100 is 100 возвращает True, а 1000 is 1000 — не гарантированно.
Важно: это деталь реализации CPython, а не часть спецификации языка. Диапазон задаётся макросами (_PY_NSMALLNEGINTS = 5, _PY_NSMALLPOSINTS = 257). Его нельзя настроить без перекомпиляции CPython. В PyPy, кстати, диапазон настраиваемый.
Начиная с Python 3.12 (PEP 683) малые целые числа стали immortal objects — подробнее об этом в разделе про управление памятью.
Строки тоже могут интернироваться автоматически (короткие, похожие на идентификаторы), а для длинных повторяющихся строк можно вызвать sys.intern() вручную:
import sys
a = sys.intern("some_long_repeated_string")
b = sys.intern("some_long_repeated_string")
print(a is b) # True — один объект в памяти
Изменяемые и неизменяемые типы
| Immutable (неизменяемые) | Mutable (изменяемые) |
|---|---|
str, bytes | list, bytearray |
int, float, complex | dict |
bool | set |
tuple | collections.deque |
frozenset | collections.Counter |
fractions.Fraction | и т.д. |
Почему immutable лучше
- Проще рассуждать — содержимое не меняется, нет сюрпризов
- Хэшируемые — можно использовать как ключи словарей и элементы множеств
- Быстрее —
tupleработает быстрееlistи занимает меньше памяти - Кэширование — immutable объекты можно безопасно кэшировать и переиспользовать
import sys
print(sys.getsizeof([1])) # 64 байта — список
print(sys.getsizeof((1,))) # 48 байт — кортеж (экономнее!)
a = list(range(100))
print(sys.getsizeof(a)) # 856 байт
b = tuple(range(100))
print(sys.getsizeof(b)) # 840 байт
Конкретные значения sys.getsizeof() зависят от платформы и версии Python. Приведённые числа — для CPython 3.12 на 64-bit системе.
Ловушка: изменяемый элемент внутри неизменяемого контейнера
Кортеж неизменяем, но если он содержит ссылку на изменяемый объект (например, list), содержимое этого объекта можно изменить:
a = (1, [2, 23, 4, 5], 3)
a[1].append(999)
print(a) # (1, [2, 23, 4, 5, 999], 3) — кортеж «изменился»!
Визуализация: Python Tutor.
Копирование объектов
Присваивание в Python не копирует объект — оно создаёт новую ссылку на тот же объект. Для изменяемых типов это может привести к неожиданному поведению:
# Присваивание — НЕ копирование!
a = [1, 2, 3]
b = a
b.append(4)
print(a) # [1, 2, 3, 4] — a тоже изменился!
Чтобы создать независимую копию, используйте модуль copy:
import copy
original = [[1, 2], [3, 4]]
# Поверхностная копия — копирует контейнер, но не вложенные объекты
shallow = copy.copy(original)
shallow[0].append(999)
print(original) # [[1, 2, 999], [3, 4]] — вложенный список изменился!
# Глубокая копия — рекурсивно копирует всё
original = [[1, 2], [3, 4]]
deep = copy.deepcopy(original)
deep[0].append(999)
print(original) # [[1, 2], [3, 4]] — оригинал не тронут
Для списков есть сокращения для поверхностной копии: b = a[:] или b = list(a).
Числовые типы
Целочисленные литералы
Python поддерживает запись чисел в разных системах счисления:
# 2-, 8-, 10- и 16-ричные литералы
print(0b11001100, 0o314, 204, 0xCC) # 204 204 204 204
print(bin(204), oct(204), str(204), hex(204))
# 0b11001100 0o314 204 0xcc
Подробнее о том, как в CPython реализованы целые числа — они поддерживают произвольную �точность (arbitrary precision), в отличие от int в C или Java.
Вещественные числа (float)
64-разрядные числа двойной точности (аналог double в C):
print(1., .1, 1.1) # 1.0 0.1 1.1
print(.1e1, 1e-1, 1.1e0) # 1.0 0.1 1.1 (экспоненциальная запись)
print(5. / .3, 5. // .3, 5. % .3) # деление, нацело, остаток
float имеет ограниченную точность (sys.float_info.epsilon ≈ 2.22e-16). Классический пример: 0.1 + 0.2 != 0.3.
Для финансовых расчётов используйте decimal.Decimal, для точных дробей — fractions.Fraction.
NoneType
Тип с единственным значением None. Предназначен для указания отсутствия значения (аналог void/null в других языках, но в Python None — полноценный объект):
print(None) # None
print(type(None)) # <class 'NoneType'>
x = None
y = 123
print(x is None) # True — всегда используйте is для сравнения с None
print(y is None) # False
print(y is not None) # True
Сравнение с None всегда выполняйте через is None / is not None, а не через == None. Оператор == может быть переопределён в классе, и результат будет непредсказуемым.
Логи�ческие операторы и bool
bool в Python наследуется от int: True == 1, False == 0. Это позволяет использовать булевы значения в арифметике (хотя делать это без необходимости не стоит):
print(bool(5)) # True — любое ненулевое число
print(bool(0)) # False
print(bool('')) # False — пустая строка
print(bool([])) # False — пустой контейнер
print(True == 1) # True — bool наследуется от int
print(True + False) # 1
print(True is 1) # False — разные объекты, хоть и равны по значению
Truthiness (правдивость)
Любой объект в Python может использоваться в булевом контексте. Считаются ложными (False): None, 0, 0.0, '', [], (), {}, set(), а также объекты, чей __bool__() или __len__() возвращает 0 / False. Всё остальное — истинно.
Ленивые операторы and и or
Операторы and и or возвращают операнды, а не булевы значения, и вычисляются лениво:
x or y— возвращаетx, еслиxистинно, иначеyx and y— возвращаетx, еслиxложно, иначеy
x = 0
print(x or 'default') # 'default' — x ложно, возвращается y
print(x and 'value') # 0 — x ложно, возвращается x
a, b = 6, 9
print(a if a > b else b) # 9 — тернарный оператор
Управляющие конструкции
Циклы
for i in range(5): # в диапазоне [0, 5)
print(i)
for c in 'abcde': # проходим по итерируемому объекту
print(c)
for i, c in enumerate('abcde'): # если нужен индекс
print(i, c)
Ветка else в циклах
Малоизвестная, но полезная конструкция: блок else выполняется, если цикл завершился нормально (не по break):
for n in range(2, 10):
for x in range(2, n):
if n % x == 0:
print(f"{n} = {x} × {n // x}")
break
else:
# выполнится, только если break не сработал
print(f"{n} — простое число")
Pattern matching (Python 3.10+)
До Python 3.10 для ветвления по значению использовались цепочки if-elif или словари с обработчиками. В 3.10 появился structural pattern matching (PEP 634):
# Старый способ — if/elif
x = 3
if x == 1:
print('one')
elif x == 2:
print('two')
elif x == 3:
print('three')
else:
print('unexpected')
# Альтернатива — dict dispatch
handlers = {1: lambda: 'one', 2: lambda: 'two', 3: lambda: 'three'}
print(handlers.get(x, lambda: 'unexpected')())
# Python 3.10+ — pattern matching
match x:
case 1:
print('one')
case 2:
print('two')
case 3:
print('three')
case _:
print('unexpected')
Pattern matching гораздо мощнее, чем switch-case: поддерживает деструктуризацию, guard-условия, маппинг типов. Для простого сравнения значений производительность сопоставима с if-elif — «дополнительные накладные расходы» проявляются только при использовании сложных паттернов (destructuring, guards).
match command.split():
case ["quit"]:
quit_game()
case ["go", direction]:
go(direction)
case ["drop", *objects]:
drop(objects)
case _:
unknown_command()
Обработка исключений
Ошибки в Python — это объекты, унаследованные от BaseException. Конструкция try-except позволяет перехватывать исключения и реагировать на них:
try:
x = int("abc")
result = 10 / x
except ValueError:
print("Ошибка: неверное преобразование в число!")
except ZeroDivisionError as e:
print(f"Ошибка: {e}")
except Exception as e:
print(f"Непредвиденная ошибка: {e}")
else:
print("Успех") # выполняется, если не было исключений
finally:
print("Всегда выполняется") # идеален для освобождения ресурсов
Используйте else для кода, который должен выполниться только при отсутствии исключений — это чётче, чем ставить его в конец try. Блок finally гарантированно выполняется всегда — используйте для закрытия файлов и освобождения ресурсов.
Exception Groups (Python 3.11+)
В Python 3.11 появились группы исключений (PEP 654) для одновременной обработки нескольких ошибок (особенно актуально для asyncio.TaskGroup):
try:
raise ExceptionGroup("multiple errors", [
ValueError("bad value"),
TypeError("bad type"),
])
except* ValueError as eg:
print(f"Value errors: {eg.exceptions}")
except* TypeError as eg:
print(f"Type errors: {eg.exceptions}")
Как работает интерпретатор CPython
Чтобы понять, почему Python работает именно так, полезно зна�ть, что происходит между python script.py и результатом на экране. CPython обрабатывает код в несколько этапов:
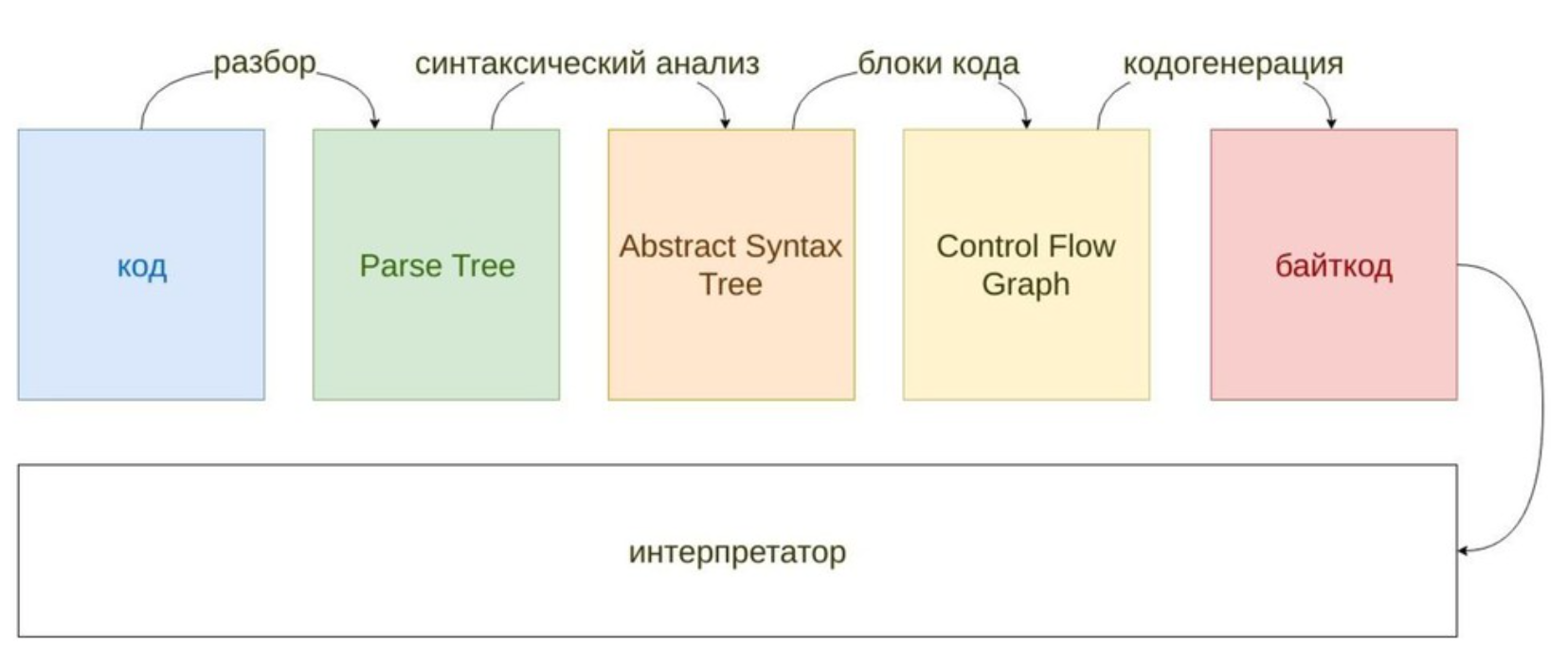
1. Лексический анализ (tokenizer)
Исходный текст разбивается на токены — базовые единицы языка:
from tokenize import tokenize
from io import BytesIO
from token import tok_name
from pprint import pprint
code_string = 'print(222*555)'
tokens = tokenize(BytesIO(code_string.encode('utf-8')).readline)
pprint([(token.string, tok_name[token.type]) for token in tokens])
# [('utf-8', 'ENCODING'),
# ('print', 'NAME'),
# ('(', 'OP'),
# ('222', 'NUMBER'),
# ('*', 'OP'),
# ('555', 'NUMBER'),
# (')', 'OP'),
# ('', 'NEWLINE'),
# ('', 'ENDMARKER')]
Подробнее: Lexical analysis — Python docs.
2. Синтаксический анализ (parser → AST)
Токены объединяются в Abstract Syntax Tree — древовидное представление структуры программы:
import ast
code = "def to_power(a, b):\n return a ** b"
tree = ast.parse(code)
print(ast.dump(tree, indent=2))
Благодаря доступу к AST из Python работают такие инструменты, как pytest (переписывает assert для информативных сообщений) и Sphinx (генерирует документацию).
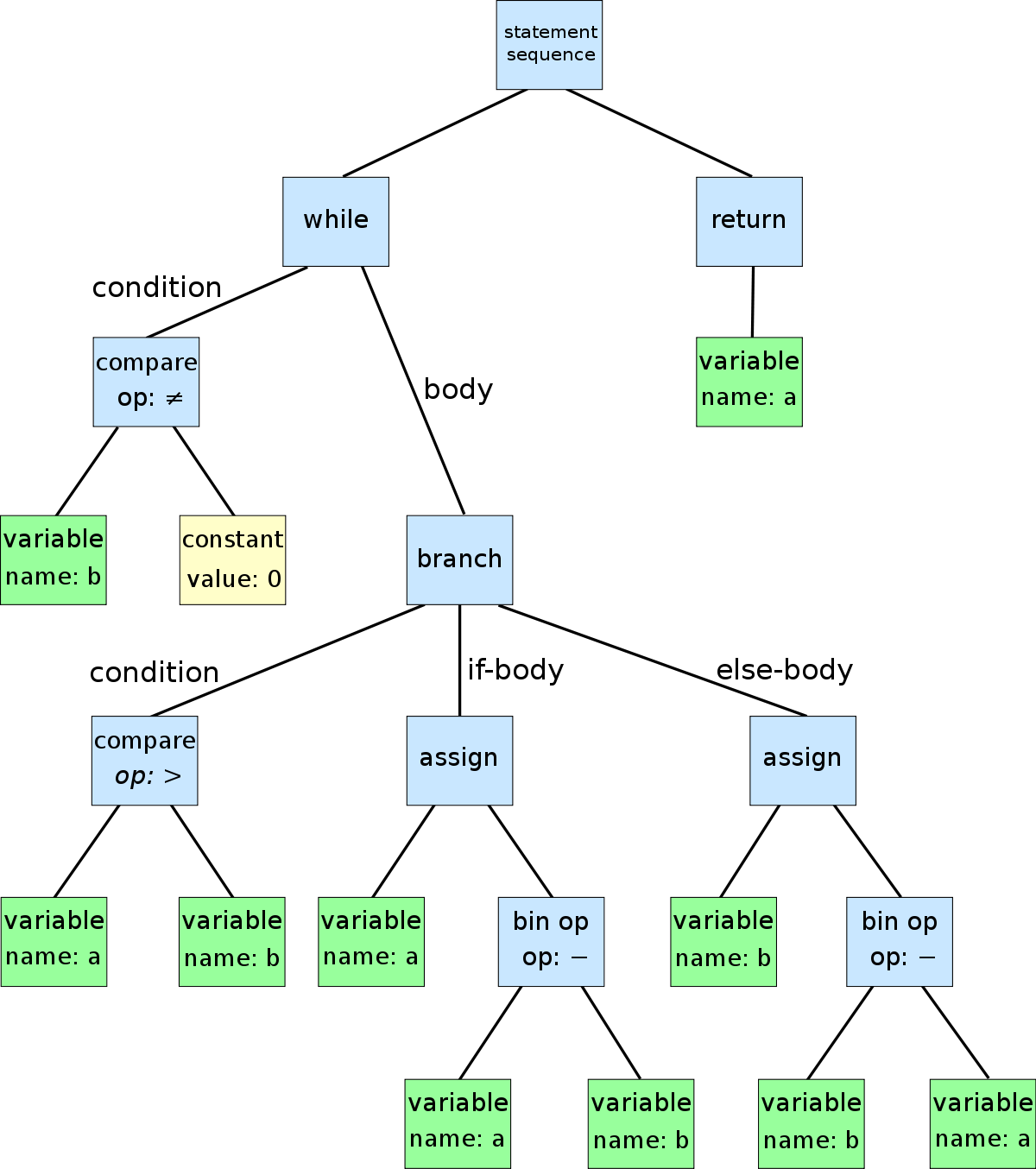
Визуализация AST для функции с циклом и условием:
3. Компиляция в байткод
AST транслируется в байткод — набор инструкций для виртуальной машины Python (PVM). Скомпилированный байткод кэшируется в файлах .pyc (�в директории __pycache__):
import dis
def add(a, b):
return a + b
dis.dis(add)
# Python 3.12+:
# RESUME 0
# LOAD_FAST 0 (a)
# LOAD_FAST 1 (b)
# BINARY_OP 0 (+)
# RETURN_VALUE
Подробнее о компиляторе: CPython Compiler Design. Документация модуля dis.
Начиная с Python 3.11 (PEP 659), CPython использует специализирующий адаптивный интерпретатор: часто выполняемые инструкции автоматически заменяются на оптимизированные версии. Например, BINARY_OP для сложения двух int специализируется в BINARY_OP_ADD_INT. Улучшенные traceback (3.11+) также стали возможны благодаря изменениям в формате байткода.
Реализация списков и словарей
Понимание внутреннего устройства структур данных помогает предсказывать производительность и выбирать правильную структуру для задачи.
Списки
Список в CPython — это динамический массив указателей на объекты. При добавлении элементов используется стратегия over-allocation — выделяется больше памяти, чем нужно, чтобы амортизировать стоимость вставок:
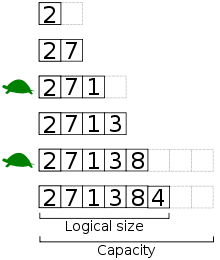
import sys
a = []
print(sys.getsizeof(a)) # 56 — пустой список
a.append(1)
print(sys.getsizeof(a)) # 88 — выделено место под 4 элемента
a.append(1)
print(sys.getsizeof(a)) # 88 — ещё есть место
for _ in range(3):
a.append(1)
print(sys.getsizeof(a)) # 120 — перевыделение
Количество выделяемых слотов растёт по формуле (newsize + (newsize >> 3) + 6) & ~3, что даёт последовательность: 0, 4, 8, 16, 24, 32, 40, 52, 64, 76, … (исходный код)
Хэш-функции
Хэш-функция отображает объект в целое число. В идеале она должна быть инъекцией (разным объектам — разные хэши), но н�а практике коллизии неизбежны.
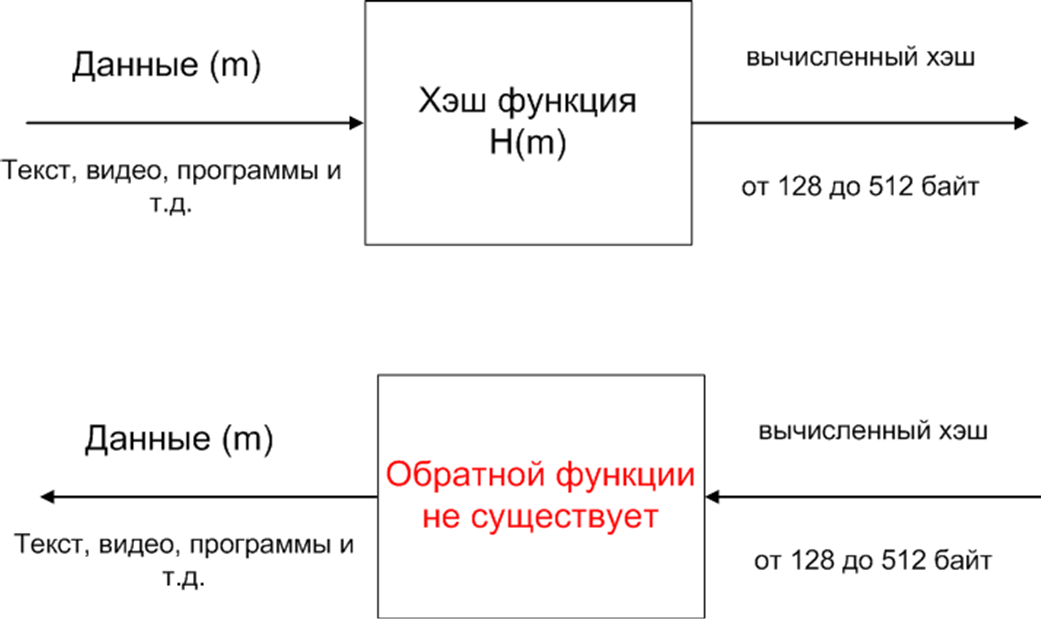
Особенности в CPython:
- Для целых чисел
hash(x) == x(за исключением-1) hash(-1)возвращает-2, потому что-1зарезервировано как индикатор ошибки в C API. Следствие:hash(-1) == hash(-2)— этоTrue(подробности на StackOverflow)- Вы можете определить свой
__hash__, но не можете возвращать -1 из него (CPython автоматически заменит на -2)
Словари
Словарь основан на хэш-таблице с открытой адресацией:
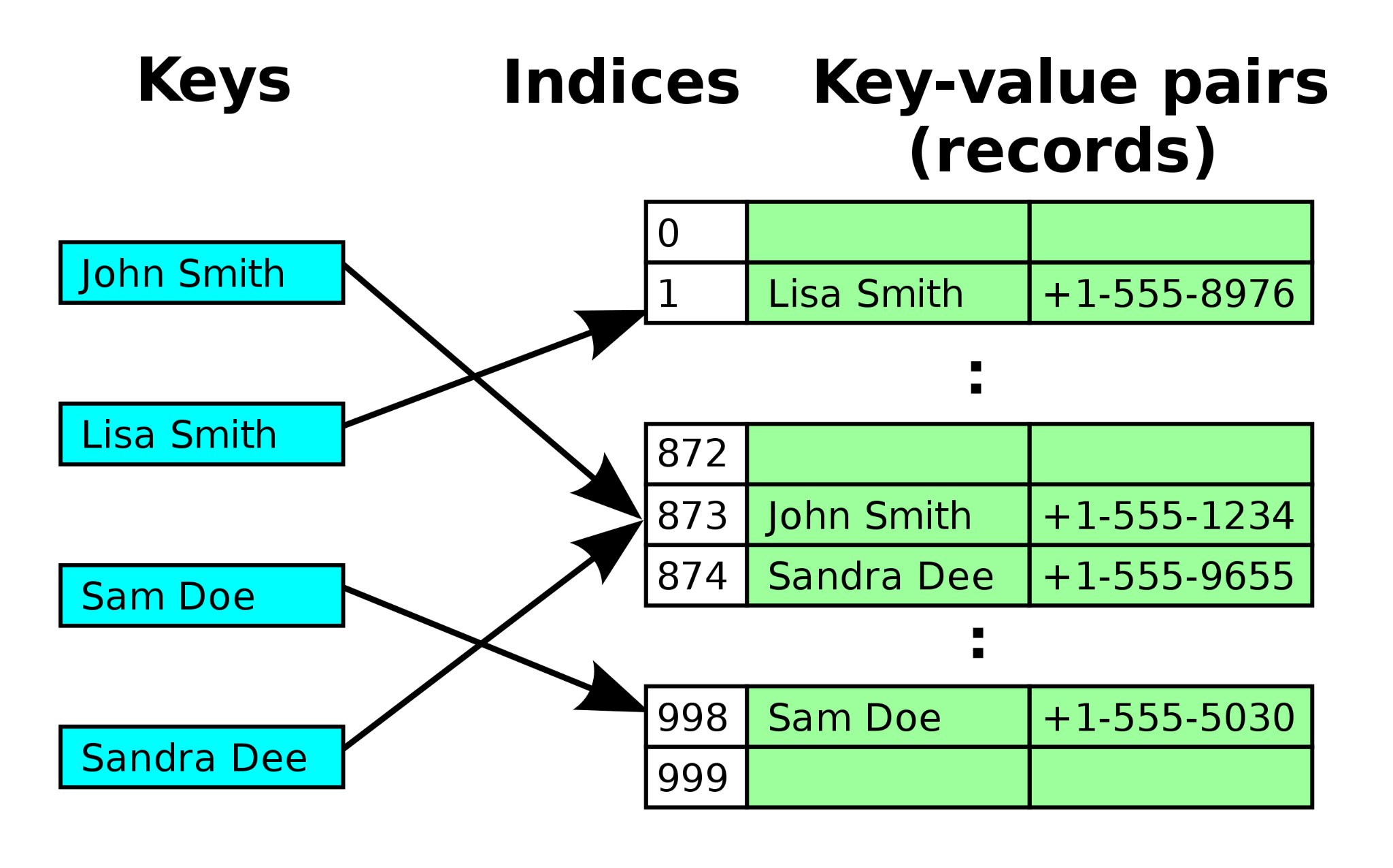
- Считаем
hash(key) - Хэш определяет позицию в массиве
- При коллизии — ищем следующий свободный слот
- Если заполненность таблицы высокая — перевыделяем с увеличением размера
Начиная с Python 3.6 словари сохраняют порядок вставки (гарантировано спецификацией с 3.7): данные и индексы хранятся отдельно, что также экономит память.
| Операция | Среднее | Худшее |
|---|---|---|
| Поиск | O(1) | O(n) |
| Вставка | O(1) | O(n) |
| Удаление | O(1) | O(n) |
Нельзя изменять словарь во время итерации — это вызовет RuntimeError:
a = {'a': 1, 'b': 2}
for key in a:
a['c'] = 3 # RuntimeError: dictionary changed size during iteration
Решение: итерируйте по копии ключей for key in list(a): или собирайте изменения и применяйте после цикла.
Работа с памятью в CPython
CPython использует трёхуровневую систему управления памятью для маленьких объектов (до 512 байт), которых в Python — подавляющее большинство:
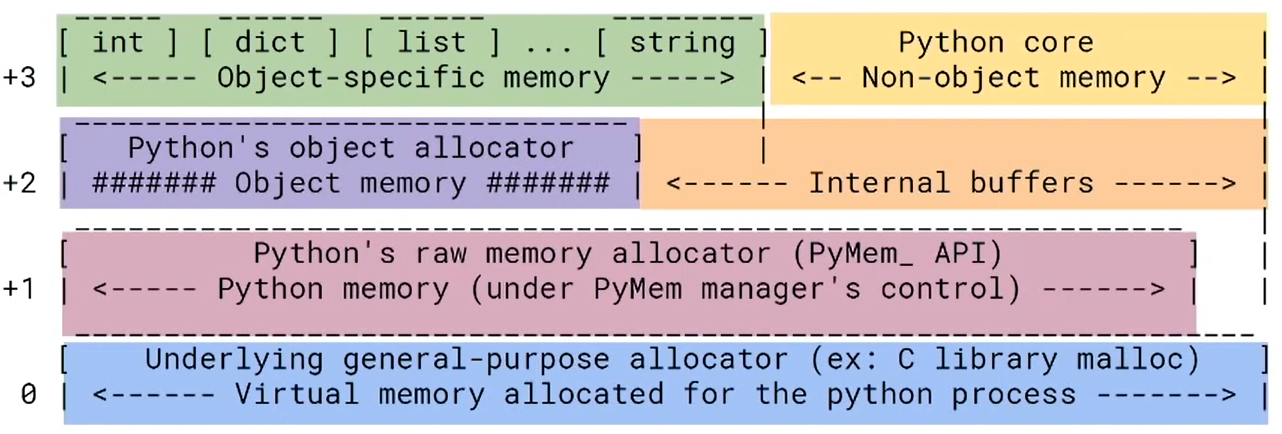
- Арены (256 КБ) — крупные блоки, запрашиваемые у ОС
- Пулы (4 КБ) — блоки внутри арены для объектов одного размера
- Блоки — фактические ячейки памяти для объектов
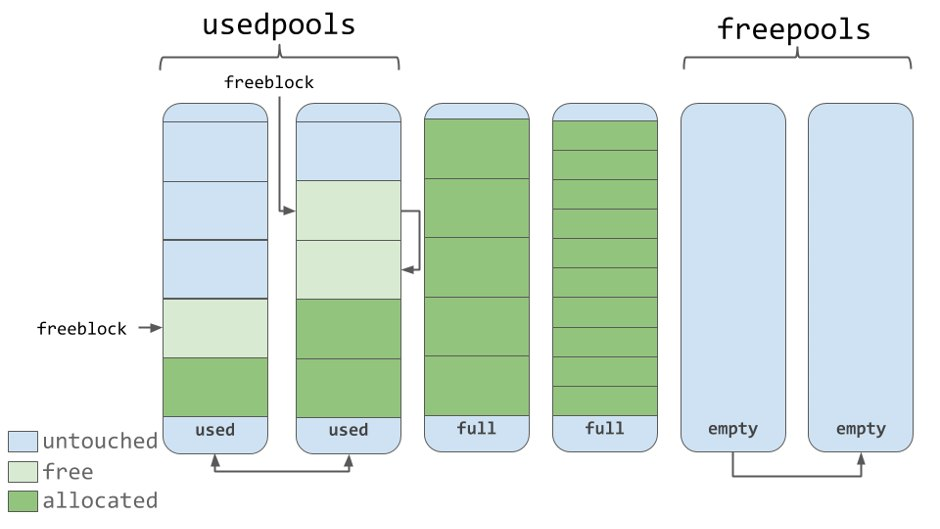
Объекты больше 512 байт аллоцируются через стандартный malloc. Арена освобождается и возвращается ОС только когда все её пулы свободны (происходит крайне редко — подробнее о возврате памяти).
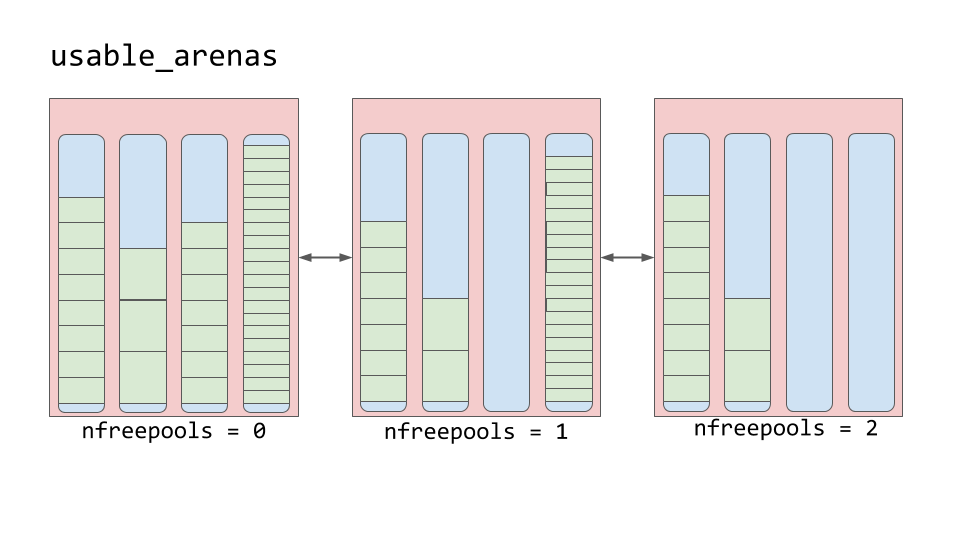
Благодаря тому, что памяти всегда выделено больше, чем нужно, аллокация маленьких объектов происходит очень быстро — нужно лишь взять блок из уже готового пула.
Подробнее: Управление памятью в Python (Хабр).
Подсчёт ссылок (reference counting)
Основной механизм управления памятью — подсчёт ссылок. Каждый объект хранит счётчик ob_refcnt. Когда счётчик достигает 0, память освобождается немедленно:
import sys
a = 'hello hello'
print(sys.getrefcount(a)) # 2 (a + аргумент getrefcount)
b = a
print(sys.getrefcount(a)) # 3
del b
print(sys.getrefcount(a)) # 2
Почему этот код даёт разные результаты?
import sys
print(sys.getrefcount("hello hello")) # одно число
a = "hello hello"
print(sys.getrefcount(a)) # другое число
Ответ: в первом случае строка "hello hello" — временный объект, единственная ссылка на который — аргумент getrefcount. Во втором — переменная a создаёт дополнительную ссылку. Подробнее: StackOverflow.
Immortal объекты (Python 3.12+)
Начиная с Python 3.12 (PEP 683), некоторые объекты стали бессмертными (immortal) — их счётчик ссылок фиксирован (равен 0xFFFFFFFF на x64) и никогда не изменяется. Py_INCREF/Py_DECREF на таких объектах — пустые операции.
Бессмертными являются:
None,True,False- Малые целые числа (−5...256)
- Встроенные типы (
int,str,list, ...) - Встроенные исключения (
Exception,ValueError, ...) - Пустые неизменяемые контейнеры (
(),b'',frozenset()) - Интернированные строки
Это означает, что sys.getrefcount(1) в Python 3.12+ вернёт очень большое число (например, 4294967295), а не реальное количество ссылок.
Зачем это нужно: immortal objects — фундамент для per-interpreter GIL (Python 3.12) и экспериментального free-threaded Python без GIL (PEP 703, Python 3.13).
Циклический сборщик мусора (GC)
Подсчёт ссылок не может обнаружить циклические ссылки — когда объекты ссылаются друг на друга:
a = [1, 2]
a.append(a) # a ссылается сам на себя — refcount никогда не станет 0
Для этого CPython использует отдельный сборщик мусора на основе алгоритма поколений (generational GC):
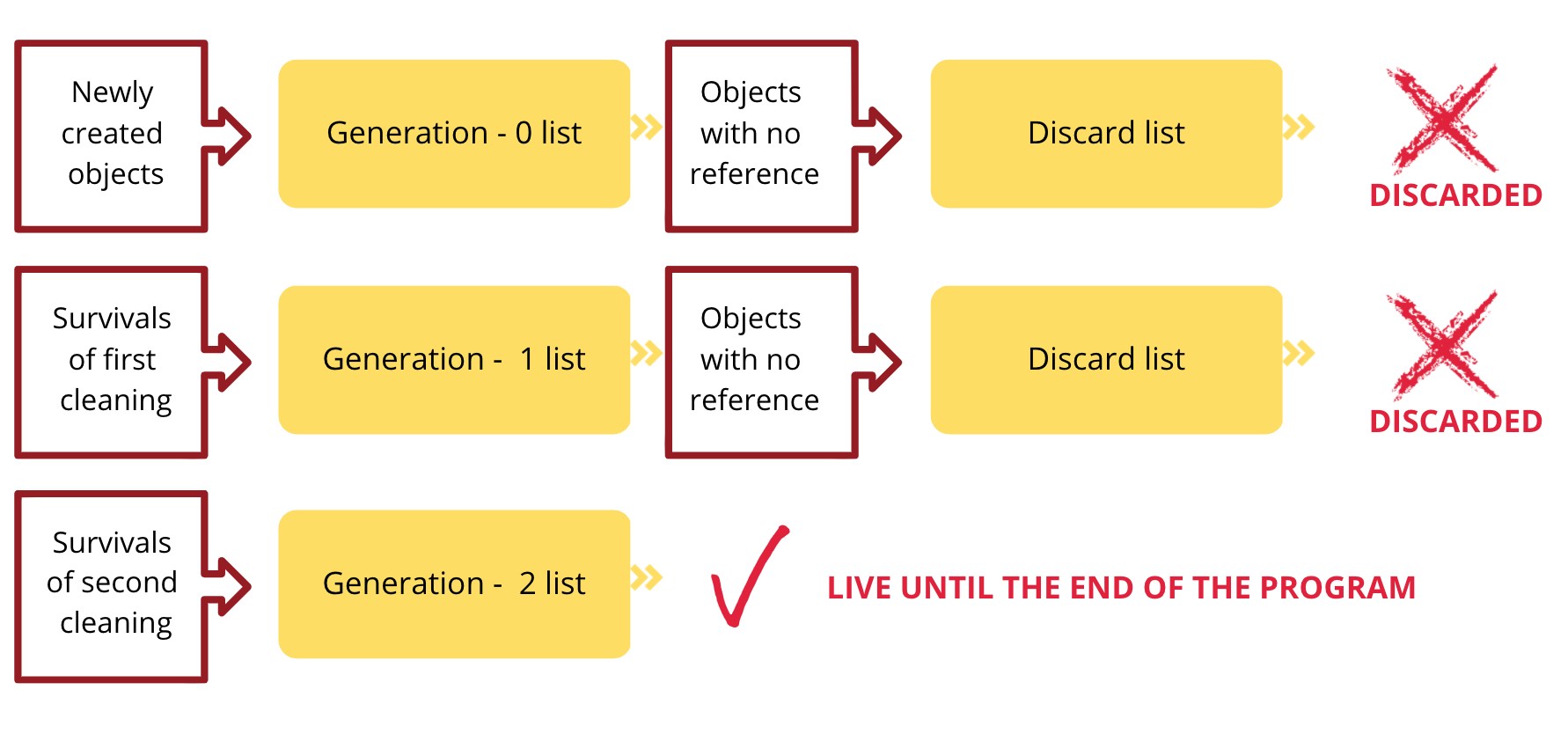
- Поколение 0 — новые объекты, проверяются часто
- Поколение 1 — пережили одну сборку
- Поколение 2 — долгоживущие объекты, проверяются редко
Предположение: чем дольше объект живёт, тем меньше вероятность, что он станет мусором.
import gc
print(gc.get_threshold()) # (700, 10, 10) — пороги для каждого поколения
gc.collect() # принудительная сборка
Для критичного по производительности кода можно временно отключить GC (gc.disable()) и запускать сборку вручную. Instagram отключили GC в своих Django-серверах и получили 10% прирост производительности. Но это нужно делать осознанно — без GC циклические ссылки приведут к утечкам памяти.
Упражнения (необязательные)
Easy
Написать функцию для поиска первых n чисел Фибоначчи.
Medium
Построить AST полученной функции. Для визуализации можно использовать networkx. Для корректного отображения кода на графе — метод ast.unparse (Python 3.9+).
Hard
Сделать отображение графа красивым: помечать разными цветами константы, вызовы функций, операторы. Подписи вершин не должны вылезать за границы. Граф должен быть похож на дерево.
С помощью парс�инга AST реализованы библиотеки вроде pytest и Sphinx.
Полезные ссылки
Видео
- Школа бэкенд-разработки Яндекса 2019 — Устройство CPython
- Как работает интерпретатор Python
- Григорий Петров — Python в 2022
- Управление памятью в Python (видео)
- Хэш-функции (видео)
Статьи и документация
- Data Model — Python docs
- Управление памятью в Python (Хабр)
- Возвращаем память ОС с помощью Python
- Dismissing Python Garbage Collection at Instagram
- PEP 572 — Assignment Expressions (walrus operator)
- PEP 636 — Structural Pattern Matching: Tutorial
- PEP 683 — Immortal Objects
- PEP 703 — Making the GIL Optional
- How Python integers work — Ten Thousand Meters
- Pointers in Python — Real Python