Функциональное программирование
Что такое функциональное программирование
Функциональное программирование (ФП) — парадигма программирования, в которой процесс вычисления трактуется как вычисление значений функций в математическом понимании. Это не конкретный синтаксис и не фреймворк — это набор идей о том, как органи�зовать код.
Три ключевых принципа ФП:
- Функции как значения — функции можно передавать, возвращать и хранить в переменных
- Избегание мутаций — предпочтение чистых функций, которые не меняют внешнее состояние
- Композиция — построение сложного поведения из простых функций
Python — не функциональный язык и не задумывался как таковой. Но это не мешает использовать подходы из ФП там, где они делают код проще и надёжнее. Документация Python включает отдельное руководство по ФП.
Функции как объекты первого класса
В Python функции — это объекты. Их можно присваивать переменным, передавать как аргументы и возвращать из других функций.
def greet(name):
return f"Hello, {name}"
say_hello = greet
print(say_hello("World")) # Hello, World
def apply(func, value):
return func(value)
print(apply(greet, "Python")) # Hello, Python
Функция первого класса (first-class function) — функция, которая может быть передана как аргумент, возвращена из другой функции и присвоена переменной. В Python все функции являются объектами первого класса.
Поскольку функция — это объект, у неё есть атрибуты:
def factorial(n):
"""returns n!"""
return 1 if n < 2 else n * factorial(n - 1)
print(factorial.__name__) # 'factorial'
print(factorial.__doc__) # 'returns n!'
print(type(factorial)) # <class 'function'>
Функции высшего порядка
Функция высшего порядка принимает другие функции как аргументы или возвращает их. Зачем это нужно? Чтобы отделить что делать от как перебирать.
Пример: нужно протестировать три алгоритма сортировки. Без функций высшего порядка пришлось бы дублировать логику проверки для каждого алгоритма. С ними — одна функция и цикл:
from sort_algs import sort1, sort2, sort3
def test_sort(sort_alg, list_to_sort, answer):
sorted_list = sort_alg(list_to_sort)
if sorted_list == answer:
return True
return False
l = [5, 4, 3, 2, 1]
answer = sorted(l)
for alg in [sort1, sort2, sort3]:
success = test_sort(alg, l, answer)
print(alg.__name__, ':', success)
При добавлении нового алгоритма достаточно добавить его в список — код проверки не меняется.
map, filter, reduce
Три классические функции высшего порядка, пришедшие в Python из Lisp:
numbers = [1, 2, 3, 4, 5]
# map — применяет функцию к каждому элементу
squared = list(map(lambda x: x**2, numbers)) # [1, 4, 9, 16, 25]
# filter — оставляет элементы, для которых функция вернула True
evens = list(filter(lambda x: x % 2 == 0, numbers)) # [2, 4]
# reduce — «сворачивает» последовательность в одно значение
from functools import reduce
total = reduce(lambda a, b: a + b, numbers) # 15
map и filter возвращают ленивые итераторы, а не списки. reduce с Python 3 перенесён в functools.
Визуализация работы reduce — последовательное «сворачивание» элементов:
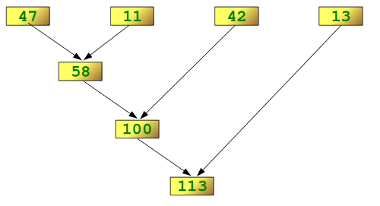
map может принимать несколько итерируемых объектов:
for x in map(lambda a, b: f'{a}+{b}', [1, 2, 3], [10, 20, 30, 40, 50]):
print(x, end=' ')
# 1+10 2+20 3+30 (останавливается по самому короткому)
zip
zip объединяет элементы из нескольких последовательностей в кортежи:
a = [1, 2, 3]
b = "xyz"
c = (None, True)
res = list(zip(a, b, c))
print(res) # [(1, 'x', None), (2, 'y', True)]
Останавливается по самому короткому итерируемому. Используйте itertools.zip_longest для дополнения до самого длинного.
Чистые функции
Чистая функция — функция без побочных эффектов. Она зависит только от своих аргументов и возвращает только свой результат, не изменяя ничего снаружи.
# Чистая: результат определяется только аргументами
def pure_function(x, y):
temp = x + 2*y
return temp / (2*x + y)
# Нечистая: изменяет внешнее состояние
some_list = []
def impure_function(arg):
some_list.append(arg)
Преимущества чистых функций:
- Тестируемость — не нужен setup/teardown, результат предсказуем
- Мемоизация — можно безопасно кешировать результат (см.
lru_cache) - Параллельность — нет общего состояния, нет гонок данных
- Предсказуемость — одни и те же аргументы всегда дают один и тот же результат
Ограничение: чистые функции усложняют ввод/вывод, который по своей природе требует побочных эффектов.
Lambda-выражения
Lambda — анонимная функция в одну строку:
add = lambda a, b: a + b
students = [("Alice", 85), ("Bob", 92), ("Charlie", 78)]
students.sort(key=lambda s: s[1], reverse=True)
Lambda-выражения ограничены одним выражением. Если у вашей lambda есть имя (вы присваиваете её переменной) — скорее всего, лучше использовать def. Lambda хороши как одноразовые функции в map, filter, sort.
Comprehensions vs map/filter
List comprehension и generator expression выполняют ту же работу, что map и filter, но более читабельны:
from math import factorial
# map
list(map(factorial, range(6))) # [1, 1, 2, 6, 24, 120]
# comprehension
[factorial(n) for n in range(6)] # [1, 1, 2, 6, 24, 120]
# map + filter
list(map(factorial, filter(lambda n: n % 2, range(6)))) # [1, 6, 120]
# comprehension
[factorial(n) for n in range(6) if n % 2] # [1, 6, 120]
Comprehension обычно понятнее, но map/filter бывают удобны при работе с уже определёнными функциями (без lambda).
Walrus-оператор := в comprehensions
Оператор присваивания := (Python 3.8+) позволяет избежать повторных вычислений внутри comprehension:
# Без walrus — f(x) вычисляется дважды:
stuff = [(lambda y: [y, x/y])(f(x)) for x in range(5)]
# С walrus — f(x) вычисляется один раз:
stuff = [[y := f(x), x/y] for x in range(5)]
# Фильтрация с сохранением вычисленного значения:
[nn for n in range(10) if (nn := factorial(n)) % 2]
Генераторы и ленивые вычисления
Ленивые вычисления — идея не проводить лишние вычисления, а исполнять только тот код, который реально понадобился. В функциональных языках это работает «из коробки», в Python нужно использовать генераторы.
Генератор — функция с yield вместо return. Она возвращает ленивый итератор, вычисляя значения по одному:
def factorials(n):
result = 1
yield result
for i in range(2, n + 1):
result *= i
yield result
gen = factorials(5)
print(next(gen)) # 1
print(next(gen)) # 2
print(next(gen)) # 6
print(next(gen)) # 24
Генератор экономит память — он не хранит все значения сразу, а вычисляет каждое при вызове next(). Генераторы запоминают, где функция была приостановлена, и продолжают с того же места.
Generator expressions
Generator expression — это comprehension в круглых скобках. В отличие от list comprehension, не создаёт список в памяти:
# List comprehension — создаёт список целиком
sum([x**2 for x in range(1_000_000)])
# Generator expression — вычисляет по одному значению
sum(x**2 for x in range(1_000_000))
Используйте generator expression вместо list comprehension, когда результат нужен только для итерации (например, передаётся в sum, max, any). Для больших данных разница в потреблении памяти может быть огромной.
Типы и аннотации типов��
Тип, класс и объект
В Python эти понятия смешиваются, но полезно их различать:
- Тип говорит, что хранится в объекте и какой у него интерфейс (какие операции доступны). Объект может иметь много типов, объекты разных классов могут иметь один тип.
- Класс говорит, как именно реализованы операции.
- Объект хранит данные и умеет работать с ними.
a: Iterable = list() # list — класс, Iterable — тип (протокол)
Несмотря на утиную типизацию, в Python строгая типизация. Типы не проверяются интерпретатором на этапе выполнения, но есть mypy для статической проверки и Pydantic для валидации данных в runtime.
Аннотации типов
Аннотации типов помогают улучшить читаемость кода, упростить отладку и использовать статическую проверку:
# Аннотации для функций:
def greet(name: str) -> str:
return f"Привет, {name}!"
# Анно�тации для переменных:
age: int = 30
# Работа с коллекциями (Python 3.12+):
numbers: list[int] | None = [1, 2, 3, 4]
# До Python 3.10:
from typing import Optional
numbers: Optional[list[int]] = [1, 2, 3, 4]
# До Python 3.9:
from typing import List, Optional
numbers: Optional[List[int]] = [1, 2, 3, 4]
Для Python 3.12+ используйте встроенные типы: list[int], dict[str, int], X | None. Импорты из typing (List, Optional, Dict) — устаревшие псевдонимы, оставленные для обратной совместимости.
Передача аргументов: call by sharing
Единственный способ передачи параметров в Python — вызов по соиспользованию (call by sharing). Каждый параметр функции получает копию ссылки на фактический аргумент. Функция может модифицировать изменяемый объект, переданный как параметр, но не может заменить его другим объектом:
def our_function(mutable, immutable):
mutable.append(1)
immutable += 1
print(f"Inside func:\timmutable={immutable},\tmutable={mutable}")
our_list, our_num = ['one'], 0
print(f"Before func:\timmutable={our_num},\tmutable={our_list}")
our_function(our_list, our_num)
print(f"After func: \timmutable={our_num},\tmutable={our_list}")
# Before func: immutable=0, mutable=['one']
# Inside func: immutable=1, mutable=['one', 1]
# After func: immutable=0, mutable=['one', 1]
Список изменился (он мутабельный, append меняет сам объект), а число — нет (оно иммутабельное, += создаёт новый объект).
Оператор += ведёт себя по-разному для разных типов:
def f(a, b):
a += b
return a
# Числа: += создаёт новый объект
a1, b1 = 1, 2
f(a1, b1) # 3
print(a1) # 1 — не изменился
# Списки: += изменяет сам объект (вызывает __iadd__)
a2, b2 = ['one'], ['two']
f(a2, b2) # ['one', 'two']
print(a2) # ['one', 'two'] — изменился!
Аргументы в деталях
Python поддерживает несколько видов параметров:
| Вид параметра | Синтаксис | Пример |
|---|---|---|
| positional-or-keyword | def func(foo, bar=None) | func(1, bar=2) |
| positional-only (3.8+) | def func(x, /) | func(1) |
| keyword-only | def func(*, kw) | func(kw=1) |
| var-positional | def func(*args) | func(1, 2, 3) |
| var-keyword | def func(**kwargs) | func(a=1, b=2) |
Пошаговое проектирование: функция minimum
Начнём с простого и будем улучшать:
# v1: два аргумента
def minimum(x, y):
return x if x < y else y
minimum(1, 2)
minimum(x=1, y=2)
minimum(y=2, x=1)
# v2: произвольное количество (но minimum() вернёт inf)
def minimum(*args):
res = float('inf')
for x in args:
res = x if x < res else res
return res
minimum(92, 10, 62) # 10
minimum() # inf — не очень правильный результат
# v3: обязательный п�ервый аргумент
def minimum(first, *rest):
res = first
for x in rest:
res = x if x < res else res
return res
minimum("hello", ",", " ", "world", '!') # ' ' — утиная типизация
# minimum() → TypeError
# v4: keyword-only параметр default
def minimum(*args, default=None):
if not args:
return default
res, *rest = args
for x in rest:
res = x if x < res else res
return res
minimum(xs, default=0) # default передаётся обязательно по имени
keyword-only параметры
Звёздочка * в списке параметров означает, что всё после неё — только по имени:
def flatten(iterable, *, depth):
"""I flatten a given iterable up to a fixed depth."""
...
flatten([0, 1, [2, [3]], 4], depth=1) # OK
flatten([0, 1, [2, [3]], 4], 1) # TypeError!
*args и **kwargs
def you_gave_me(*args, **kwargs):
return args, kwargs
args, kwargs = you_gave_me(1, 2, a=3, b=4)
# args = (1, 2)
# kwargs = {'a': 3, 'b': 4}
def call_me(*args, **kwargs):
return args, kwargs
call_me({"a": 92}) # (({'a': 92},), {}) — dict как позиционный аргумент!
call_me(**{"a": 92}) # ((), {'a': 92}) — dict распакован как kwargs
Без ** словарь становится обычным позиционным аргументом, а не набором keyword-аргументов.
Ловушка изменяемых значений по умолчанию
Значения по умолчанию вычисляются один раз в момент определения функции. Для �неизменяемых типов это безопасно:
def foo(data="a"): # str — неизменяемое
data += chr(ord(data[-1]) + 1)
print(data)
foo() # ab
foo('bc') # bcd
foo() # ab — каждый раз одинаково
Для изменяемых — нет:
def foo(data=[0, 1]): # list — изменяемое
data += [data[-1] + data[-2]] # list.+= изменяет сам объект
print(data)
foo() # [0, 1, 1]
foo() # [0, 1, 1, 2] — тот же список!
foo() # [0, 1, 1, 2, 3]
foo([100, 500]) # [100, 500, 600] — свой список
foo() # [0, 1, 1, 2, 3, 5] — продолжается!
Решение — использовать None как sentinel:
def foo(data=None):
if data is None:
data = [0, 1] # каждый раз новый список
data += [data[-1] + data[-2]]
print(data)
foo() # [0, 1, 1]
foo() # [0, 1, 1] — теперь OK
Области видимости и правило LEGB
Пространства имён
Пространство имён (namespace) — множество ссылок переменных на объекты в памяти:
- builtins —
int,str,float,abs,id,max, ... - global — то, что на верхнем уровне скрипта
- local (namespace функции) — создаётся в момент вызова функции, уничтожается при возврате
Условные операторы и циклы не создают локальных namespace — они работают в текущем пространстве имён.
Правило LEGB
При обращении к переменной Python ищет её по вложенным областям видимо�сти — от самой внутренней к самой внешней:
Порядок поиска:
- Local — текущая функция
- Enclosing — охватывающие функции (для вложенных)
- Global — верхний уровень модуля
- Built-in — встроенные имена
global_var = 0
def func(arg1, arg2):
var = 'var'
def print_var():
# LEGB: Local -> Enclosing -> Global -> Built-in
inner_var = 1
print(inner_var) # Local — 1
print(var) # Enclosing — 'var'
print(global_var) # Global — 0
print(list) # Built-in — <class 'list'>
print_var()
func('one', 'two')
global и nonlocal
По умолчанию внутри функции можно читать внешние переменные, но изменять — нет. Для изменения нужны ключевые слова global и nonlocal:
global_var = 0
def func():
global global_var # объявляем, что будем изменять глобальную
global_var = global_var + 1
print(global_var) # 0
func()
print(global_var) # 1
def func():
var = 0
def inner():
nonlocal var # ищет в ближайшем enclosing scope (не global!)
var += 1
inner()
print(var)
func() # 1
nonlocal ищет переменную по всем охватывающим функциям (не только на один уровень выше), но не заходит в global scope. Если переменная не найдена ни в одном enclosing scope — SyntaxError.
Замыкания (closures)
Замыкание — функция, в теле которой присутствуют ссылки на переменные из окружающего кода (свободные переменные). Замыкание «захватывает» эти переменные и сохраняет к ним доступ даже после завершения охватывающей функции.
def make_multiplier(factor):
def multiply(x):
return x * factor
return multiply
double = make_multiplier(2)
triple = make_multiplier(3)
print(double(5)) # 10
print(triple(5)) # 15
Замыкание в действии: make_averager
def make_averager():
series = []
def averager(new_value):
series.append(new_value)
total = sum(series)
return total / len(series)
return averager
g = make_averager()
print(g(10)) # 10.0
print(g(10)) # 10.0
print(g(40)) # 20.0
print(g(10)) # 17.5
Список series — свободная переменная замыкания. Он создаётся один раз при вызове make_averager() и сохраняется в замыкании averager. Каждый последующий вызов g(...) работает с тем же списком.
Версия без хранения всех значений (с nonlocal):
def make_averager():
total, counter = 0, 0
def averager(new_value):
nonlocal total, counter
total += new_value
counter += 1
return total / counter
return averager
Late binding в замыканиях:
funcs = [lambda x: x + i for i in range(3)]
print(funcs[0](0)) # 2 (а не 0!)
# Все три lambda ссылаются на одну переменную i,
# которая к моменту вызова равна 2
# Исправление — значение по умолчанию:
funcs = [lambda x, i=i: x + i for i in range(3)]
print(funcs[0](0)) # 0 — теперь правильно
Декораторы
Декоратор — вызываемый объект, который принимает функцию и возвращает другую функцию (или ту же, но модифицированную). Запись с @ — синтаксический сахар:
# Это:
@decorate
def target():
print('Running target()...')
# Эквивалентно:
def target():
print('Running target()...')
target = decorate(target)
Пример: таймер
import time
import functools
def timer(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start = time.perf_counter()
result = func(*args, **kwargs)
print(f"{func.__name__} took {time.perf_counter() - start:.4f}s")
return result
return wrapper
@timer
def slow_function():
time.sleep(1)
Без @functools.wraps(func) декорированная функция «потеряет» свои атрибуты — __name__, __doc__, __module__ станут атрибутами обёртки wrapper. Всегда используйте @wraps.
Декораторы с аргументами
Если декоратору нужны параметры, добавляется ещё один уровень вложенности:
import functools
def repeat(n):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
for _ in range(n):
result = func(*args, **kwargs)
return result
return wrapper
return decorator
@repeat(3)
def say_hello():
print("Hello!")
Каррирование и частичное применение
Каррирование
Каррирование — приём из ФП, при котором функция нескольких аргументов разбивается на цепочку функций, каждая из которых принимает один аргумент:
def greet_curried(greeting):
def greet(name):
print(greeting + ', ' + name)
return greet
greet_hello = greet_curried('Hello')
greet_hello('German') # Hello, German
greet_hello('Ivan') # Hello, Ivan
greet_curried('Hi')('Roman') # Hi, Roman
functools.partial
partial фиксирует часть аргументов, создавая новую функцию с меньшим числом параметров:
from functools import partial
def power(base, exponent):
return base ** exponent
square = partial(power, exponent=2)
cube = partial(power, exponent=3)
print(square(5)) # 25
print(cube(3)) # 27
Разница: каррирование разбивает функцию на вложенные однопараметрические функции, а partial фиксирует произвольные аргументы существующей функции.
Модуль functools
lru_cache — мемоизация
from functools import lru_cache
@lru_cache(maxsize=128)
def fibonacci(n):
if n < 2:
return n
return fibonacci(n - 1) + fibonacci(n - 2)
fibonacci(100) # мгновенно благодаря кешу
lru_cache работает только с хэшируемыми аргументами. Для функций с dict/list аргументами конвертируйте их в tuple/frozenset. Для простого кеша без ограничения размера используйте functools.cache (Python 3.9+) — это lru_cache(maxsize=None).
singledispatch — перегрузка по типу
from functools import singledispatch
@singledispatch
def process(arg):
print(f"Default: {arg}")
@process.register(int)
def _(arg):
print(f"Integer: {arg * 2}")
@process.register(str)
def _(arg):
print(f"String: {arg.upper()}")
process(42) # Integer: 84
process("hello") # String: HELLO
process([1, 2]) # Default: [1, 2]
Модуль itertools
itertools предоставляет эффективные итераторы для комбинаторных задач:
import itertools
# Объединение нескольких итерируемых
list(itertools.chain([1, 2], [3, 4])) # [1, 2, 3, 4]
# Срез из итератора
list(itertools.islice(range(100), 5, 10)) # [5, 6, 7, 8, 9]
# Декартово произведение
list(itertools.product('AB', [1, 2])) # [('A',1), ('A',2), ('B',1), ('B',2)]
# Сочетания
list(itertools.combinations('ABC', 2)) # [('A','B'), ('A','C'), ('B','C')]
# Группировка (Python 3.12+)
list(itertools.batched('ABCDEFG', 3)) # [('A','B','C'), ('D','E','F'), ('G',)]
# Попарная итерация (Python 3.10+)
list(itertools.pairwise([1, 2, 3, 4])) # [(1,2), (2,3), (3,4)]
Алгебраические типы данных
Алгебраический тип данных (АТД) — тип, являющийся композицией других типов. Это проще, чем ООП: не нужно продумывать иерархию классов, достаточно описать данные.
Тип-сумма и тип-произведение
- Тип-сумма — значение является одним из вариантов (Enum, Union)
- Тип-произведение — значение является комбинацией полей (dataclass)
from dataclasses import dataclass
from enum import Enum
class Role(Enum):
Administrator = 0
Editor = 1
Reader = 2
@dataclass(frozen=True)
class User:
name: str
role: Role
is_active: bool
Пример моделирования вариантов авторизации:
from dataclasses import dataclass
@dataclass(frozen=True)
class SignInWithEmail:
email: str
password: str
@dataclass(frozen=True)
class SignInWithSms:
phone_number: str
code: str
@dataclass(frozen=True)
class SignInWithSecretToken:
token: str
SignInMethod = SignInWithEmail | SignInWithSms | SignInWithSecretToken
Преимущество АТД: можно описать предметную область так, что невалидные данные станут непредставимыми.
Pattern matching (Python 3.10+)
match/case — идеальный инструмент для работы с алгебраическими типами. Он позволяет деструктурировать объекты и проверять их тип в одном выражении:
def handle_sign_in(method: SignInMethod) -> str:
match method:
case SignInWithEmail(email=email):
return f"Signing in with email: {email}"
case SignInWithSms(phone_number=phone):
return f"Sending code to: {phone}"
case SignInWithSecretToken(token=token):
return f"Token auth: {token[:8]}..."
handle_sign_in(SignInWithEmail("user@example.com", "pass123"))
# 'Signing in with email: user@example.com'
dataclass
Декоратор @dataclass автоматически генерирует __init__, __repr__, __eq__ и другие методы:
# Без dataclass:
class RegularBook:
def __init__(self, title, author):
self.title = title
self.author = author
# С dataclass — эквивалентно:
from dataclasses import dataclass
@dataclass
class Book:
title: str
author: str
Монады
Монада — способ в функциональных языках обрабатывать «неудобные» задачи: обработку ошибок, ввод-вывод, работу с отсутствующими значениями. Можно воспринимать монаду как паттерн проектирования — контейнер, который знает, как связывать вычисления в цепочку.
Проблема, которую решают монады — цепочки проверок, где каждый шаг может упасть:
# Без монады — вложенные try/except
def process_user(data):
try:
user = parse_user(data)
except ValueError:
return None
try:
validated = validate(user)
except ValidationError:
return None
return save(validated)
С монадой цепочка становится линейной. Если на каком-то шаге ошибка — остальные шаги автоматически пропускаются:
from returns.result import Result, Success, Failure
def parse_user(data: dict) -> Result[User, str]:
if 'name' not in data:
return Failure("Missing name")
return Success(User(data['name']))
# bind связывает шаги: Failure на любом шаге → цепочка обрывается
result = (
parse_user(data)
.bind(validate)
.bind(save)
)
Три операции монады:
- unit (
Success/Failure) — оборачивает значение в монаду - bind — связывает монады в цепочку
- обрыв — если шаг не может продолжить, остальные пропускаются
Для работы с монадами в Python есть библиотека returns.
Полезные библиотеки
| Библиотека | Описание |
|---|---|
| functools | Стандартная библиотека: partial, lru_cache, singledispatch, wraps |
| itertools | Стандартная библиотека: эффективные итераторы для комбинаторных задач |
| Toolz | Легковесная библиотека, расширяющая functools/itertools |
| More-itertools | 200+ дополнительных итераторов |
| returns | Монады для Python: Result, Maybe, IO |
Полезные ссылки
- Функциональное программирование для всех — обзорная статья
- Введение в ФП на Python
- Functional Programming HOWTO — официальное руководство Python
- Лекция CS центра про функции (2018)
- Лекция CS центра (2015) — в конце презентации важные примеры кода
- Чистое ФП — выступление
- Курс на Stepik: области видимости
- LEGB Rule — примеры
- Видеоурок: области видимости
- Видео: замыкания
- Про монады
- Типизированный Python для профессиональной разработки (2022)